



فهرست مطالب
عنوانصفحه
فهرست مطالب... ح
فهرست شکل هاذ
فهرست جدول هار
چکیده...............................................................................................................................................................................1
فصل اول :مقدمه 2
1-1 مقدمه ........................................................................................................................................ 3
1-2 بیان مسئله..............4
1-3 سوالات اصلی پژوهش.... 5
1-4اهداف مسئله. 5
1-5 اهمیت و ضرورت انجام تحقیق.. 6
1-6 هدف تحقیق.. 6
1-7روش تحقیق.. ......................................................................................................................................6
1-8 جنبه جديد بودن و نوآوري در تحقيق.. 7
1-9 ساختار پایاننامه. 7
فصل دوم :مروری بر ادبیات موضوع 8
2-1 بررسی پیشینه روشهای تشخیص بیماری برمبنای الگوریتمهای مختلف.... 9
2-2 تشخیص بیماری و عوارض آن، مبتنی بر تلفیق تکنیکهای طبقهبندی و الگوریتمهای فراابتکاری.. 9
2-3 روشهای مبتنی بر شبکه عصبی.. 15
2-4 روشهای مبتنی بر درخت تصمیم.. 16
2-5 روش های مبتنی بر بیز. 18
2-6 روشهای برگرفته از منطق فازی.. 19
2-7 روشهای مبتنی بر KNN.. 19
2-8 روشهای برگرفته از هوش جمعی.. 18
2-9 راهکارهای برگرفته از ماشین بردار پشتیبان.. 18
2-10 طبقهبندهای مبتنی بر قواعد.. 19
2-11بررسی اجمالی مقالات با روشهای مختلف تشخیص بیماری و عوارض آن.. 24
فصل سوم:روش تحقیق 28
3-1داده کاوی و دسته بندی دادهها27
3-2 شبکه عصبی.. 29
1-2-3مفهوم شبکه. 26
2-2-3 شبکهعصبی چند لایه. 26
3-2-3مدل رياضي شبكهعصبي مصنوعي.. 27
4-2-3 پرسپترون چندلایه. 28
3-2-5 آموزش شبکه عصبی مصنوعی.. 29
1-5-2-3روش ارائه يكجا35
2-5-2-3 روش ارائه الگو. 30
6-2-3 الگوريتم پسانتشارخطا35
3-3 منطق فازی 38
1-3-3سیستمهایاستنتاج عصبی فازیتطبیقی.. 39
1-1-3-3ساختارسیستمهایاستنتاجعصبی فازیتطبیقی.. 39
3-3-1-2 الگوریتم ترکیبی یادگیری ANFIS.. 41
3-4 طبقهبند نزدیکترین همسایه (KNN). 42
3-5درخت تصمیم.. 42
3-5-1 اهداف اصلي درختهاي تصميمگيري دستهبندي كننده. 43
3-5-2 جذابیت درختان تصمیم.. 44
3-5-3 انواع درختان تصمیم.. 44
3-6 ماشینهای بردار پشتیبان (SVM)45
3-7طبقه بند بیزین........................................................................................................................................................46
3-8 الگوریتم های مبتنی بر هوش جمعی.. 46
3-9 الگوریتم ژنتیک..... 47
3-10الگوریتم PSO.. 47
3-11کلونی زنبور عسل..............................................................................................................................................49
3-12الگوریتم گرگ خاکستری.. 51
3-13الگوریتم GBC.. 51
3-14الگوریتم کلونی زنبور-ژنتیک(GBC ). 52
فصل چهارم:روش پیشنهادی وپیادهسازی 53
4-1 مطالعه کتابخانههای و مروری بر الگوریتم های موجود. 54
4-2جمع آوری داده ها مربوط به بیماری سندروم متابولیک.........................................................................................54
4-3 پیشپردازش دادهها56
4-3-1 پاکسازی داده ها57
1-1-3-4دستهبندی ویژگی شاخص توده بدنی................................................................................................. 57
4-3-1-2دسته بندی ویژگی فشارخون بالا........................................................................................................58
4-3-1-3دسته بندی قندخون..............................................................................................................................58
4-3-1-4دسته بندی ویژگی کلسترول...............................................................................................................59
5-1-3-4دستهبندی ویژگی تريگليسريد.. 60
2-3-4 جمیع دادهها53
3-3-4تبدیل دادهها61
4-4 ابزارهای لازم برای پیادهسازی روش پیشنهادی.. 61
4-5 چگونگی ارزیابی و ابزارهای مورد استفاده برای ارزیابی روش پیشنهادی.. 62
4-6 مراحل پیشبینی سندروم متابولیک..... 62
4-7 ایجاد مدل تشخیص سندرم متابولیک توسط الگوریتم ABC.. 63
4-8ضعف الگوریتمABCدرتشخیص سندروم متابولیک............................................................................................64
9- 4 ایجاد مدل تشخیص سندروم متابولیک توسط الگوریتمGBCاصلاح شده......................................................................64
4-9-1مرحله نمایش و مقداردهی اولیه. 65
4-9-2مرحله زنبورعسل کارگر. 66
4-9-3 مرحله زنبورعسل ناظر. 66
4-9-4 مرحله زنبورعسل دیده بان........................................................................................................................67
10-4 ساخت مدل نهایی با بکارگیری الگوریتم GBCاصلاح شده و شبکهعصبی......................................................68
11-4 نوآوری...........................................................................................................................................................70
12-4 نحوه ارزیابی مدل پیشنهادی..............................................................................................................................71
فصل پنجم:مقایسه و ارزیابی 72
5-1 نتایج شبیهسازی.. 73
فصل ششم:نتیجه گیری 78
6-1مروری بر مطالب... 79
6-2 پیشنهاد برای کارهای آتی.. 79
3-6 نتیجه گیری..........................................................................................................................................................80
مراجع. 81
فهرست شکل ها
عنوانصفحه
شکل3-1- يك نمونه عصب واقعي.. 31
شکل3-2- مدل ریاضی ساده شده عصب واقعی.. 32
شکل3-3- پرسپترون سه لايه با اتصالات كامل.. 33
شکل3-4- رفتار تابع سيگموئيد.. 34
شکل3-5- معماری ANFIS.. 40
شکل3-6- فلوچارت الگوریتم GBC... 52
شکل 4-1-مراحل الگوریتم پیشبینی سندروم متابولیک..... 62
شکل4-2-همبری یکنواخت... 67
شکل4-3- عملگر جهش.... 68
شکل-4- 4- ساختار راه حل برای الگوریتم GBC... 68
شکل4-5- ساختار شبکه عصبی مصنوعی.. 69
شکل4-6- روندنمای رهیافت پیشنهادی.. 69
شکل5‑1-درصد خطا برای پیشبینی سندرم متابولیک در مدل پیشنهادی.. 74
شکل5‑2- نمودار نتایج با معیار Accuracy.. 75
فهرست جدول ها
عنوانصفحه
جدول 2-1- استفاده از تکنیکهای طبقهبندی در تشخیص بیماری و عوارض آن.. 22
جدول 2-2- تلفیق تکنیکهای طبقهبندی و الگوریتمهای فراابتکاری در تشخیص بیماری و عوارض آن.. 23
جدول3-1- انواع توابععضویت مورد استفاده در ANFIS.. 35
جدول 4-1 نحوه نرمال سازی مجموعه دادهها55
جدول 4-2- نحوه دستهبندی شاخص توده بدنی.. 58
جدول 4-3- نحوه دستهبندی فشار خون سیستولی و دیاستولی.. 58
جدول4-4- نحوه دستهبندی قند خون.. 59
جدول 4-5- نحوه دستهبندی کلسترول.. 59
جدول 4-6- نحوه دستهبندی HDL... 59
جدول 4-7- نحوه دستهبندی LDL... 52
جدول 4-8- نحوه دستهبندی تریگلیسرید.. 53
جدول4-9- وزن دار کردن ویژگی ها66
جدول5‑1- پارامترهای مورد نیاز برای ارتباط بین کلاس های واقعی و کلاس های پیش بینی شده. 65
جدول 5-2- مقایسه نتایج با معیار Sensitivity.. 75
جدول-5-3- مقایسه نتایج با معیار Specificity.. 75
جدول 5-4- مقایسه نتایج با معیار Precision.. 76
جدول 5-5- مقایسه نتایج با معیار F-Measure. 76
جدول 5-6- مقایسه نتایج پیشبینی بیماری با معیارهای TP، FP، TN، FN، Sensitivity،77
سندروم متابولیک مجموعه ای از اختلالات در متابولیسم یا سوخت و ساز بدن است که احتمال بروز بسیاری از بیماریها از جمله بیماریهای قلبی و عروقی،دیابت و پرفشاری خون را افزایش داده و مرگ و میر ناشی از این بیماریها را در شخص مبتلا افزایش میدهد. با توجه به افزایش شیوع این اختلال، انجام پژوهشهایی در جهت پیشگیری از ابتلا به این اختلال ضروری می باشد. داده هانشان میدهد که ابتلا به این بیماریها به رغم انتشار گسترده، از طریق پردازش پرونده پزشکی بیمار قابل شناسايي و معالجه است. روشهاي داده کاوي میتوانند به کاهش تعداد پاسخها و نتایج مثبت کاذب و منفی کاذب درتصمیمگیري پزشکان کمک کنند.به دلیل وجود پارامترها و ویژگیهای مختلف، تشخیص صحیح بیماری برای پزشکان دشوار می باشد. از اهداف این پژوهش، استفاده از الگوها و روابط بین تعداد زیادي از متغیرها در پرونده بیماران برای شناسایی و پیشبینی بیماری و کمک به پزشک برای تشخیص دقیقتر میباشد. در اين پژوهش یک سیستم پشتیبان تصمیمگیری برای کمک به تشخيص و پيشبيني سندرم متابولیک ارائه خواهد گردید. در این پژوهش از داده های جمع آوری شده از بیمارستان شهدای کارگر یزد که شامل اطلاعات 1499 نمونه با 15 ویژگی است استفاده شده و سپس به ارائهی مدلی برای طبقهبندی مجموعه داده ها با استفاده از شبکهی عصبی پرسپترون چند لایه پرداخته میشود.
کلمات کلیدی : شبکههای عصبی پرپسترون چند لایه1، الگوریتم ژنتیک زنبور عسل2،الگوریتم بهینهسازی ازدحام ذرات3،
فصل اول
مقدمه
در سالهاي اخیر، میزان شیوع بیماري قلبی- عروقی و دیابت روند رو به رشدي داشته و دادهها نشان میدهد که ابتلا به این بیماریها به رغم انتشار گسترده، از طریق پردازش پرونده پزشکی بیمار قابل شناسايي و معالجه است. استفاده از تکنیک های دادهکاوی در تشخیص بیماریها روند رو به رشدی داشته است. دادهکاوی نه تنها موجب استفاده بهینه از انبوه دادههای ذخیره شده توسط سیستم های کلینیک شده بلکه موجب کشف دانش موجود در میان این دادهها نیز شده است تشخیص سندرم متابولیک از جمله مسائلی است که پزشکان این حیطه را با چالشهایی مواجه ساخته است. تشخیص زود هنگام سندرم متابولیک شانس درمان موفقیتآمیز بیمار را بالا میبرد. به دلیل وجود پارامترها و ویژگیهای مختلف، تشخیص صحیح بیماری برای پزشکان دشوار می باشد. روش پیشنهادی برای کمک به تشخيص و پيشبيني بیماریهای داخلی از طریق تکنیکهای دادهکاوی، دقیقتر از روشهای موجود، به عنوان سیستم پشتیبان تصمیمگیری در سیستمهای پزشکی کاربرد خواهد داشت. در این پژوهش سندرم متابولیک مورد بررسی قرار میگیرد. سپس یکی از بیماریها برای پژوهش انتخاب میشود. انتخاب نوع بیماری برای پژوهش اهمیت بسیاری دارد. از اهداف این پژوهش، استفاده از الگوها و روابط بین تعداد زیادي از متغیرها در پرونده بیماران برای شناسایی و پیش بینی بیماری و کمک به پزشک برای تشخیص دقیقتر میباشد. در اين پژوهش یک سیستم پشتیبان تصمیمگیری برای کمک به تشخيص و پيشبيني سندرم متابولیک ارائه خواهد گردید. بهرهگیری از راهکار دادهکاوی با رویکرد استخراج دانش از اطلاعات موجود در راستای اهدافی چون نحوه تشخیص بیماری، کاهش هزینههای درمانی و میزان خطای نحوه درمان موثر بوده و موجب بهبود عملکرد سازمانهای بهداشتی میشود [1]. مطالعات مختلف نشان دادهاند که وجود سندرم متابولیک تاثیر به سزایی روی فراوانی مرگ و میر ناشی از بیماریهای قلبی-عروقی دارد. سندرم متابولیک به عنوان مجموعهای از اختلالات متابولیکی شامل پرفشاری خون، چاقی، اختلال لیپیدها و افزایش مقاومت به انسولین از جمله عوامل تاثیرگذار در بروز مرگ و میر و ناتوانی ناشی از بیماریهای قلبی-عروقی تلقی میشود [2]. مطالعات مختلف نشان دادهاند که فراوانی شیوع این سندرم بالا است. مطالعات بسیاری در خصوص ارتباط این سندرم با وجود عوامل خطرساز بیماریهای قلبی-عروقی از جمله دیابت، پرفشاری خون، اختلالات لیپیدی، چاقی، بیتحرکی و سیگار انجام شده است و در برخی از موارد به نظر میرسد این اختلالات در دوران جنینی آغاز شده و عامل ژنتیک در بروز آن مؤثر باشد [2]. اگر چه وجود سندرم متابولیک با افزایش احتمال مرگ و میر ناشی از بیماریهای قلبی عروقی ارتباط دارد اما به نظر میرسد این احتمال خطر مستقل از سایر عوامل خطرساز مثل سن، سطح LDL کلسترول سرمی و استعمال دخانیات عمل میکند [3]. در این راستا در مطالعه حاضر کوشش میشود تا با استفاده از پردازش تکاملی برای تعیین وزنهای بهینهی شبکه عصبی MLP، سندرم متابولیک تشخیص داده شود. این فصل جهت آشنایی با کلیات تحقیق تنظیم میشود. در این فصل به چالشهای مهم در زمینه تشخیص سندرم متابولیک با استفاده از دادهکاوی پرداخته میشود. در پایان فصل نیز ساختار پایان نامه بیان میشود.
بيماريهاي قلبی-عروقی از علل از دست رفتن سالهاي عمر محسوب مي شود. با توجه به نقش سندرم متابولیک در کنترل بیماریهای قلبی-عروقی و دیابت، تشخیص سندرم متابولیک دارای اهمیت است. در سالهاي اخیر، میزان شیوع بیماري قلبی-عروقی و دیابت روند رو به رشدي داشته و دادهها نشان میدهد که ابتلا به این بیماریها به رغم انتشار گسترده، از طریق پردازش پرونده پزشکی بیمار قابل شناسايي و معالجه است. تشخیص صحیح بیماری باعث افزایش احتمال درمان قطعی میشود. روشهاي داده کاوي میتوانند به کاهش تعداد پاسخها و نتایج مثبت کاذب[1] و منفی کاذب[2] درتصمیم گیري پزشکان کمک کنند [3].
مبلغ واقعی 18,000 تومان 5% تخفیف مبلغ قابل پرداخت 17,100 تومان

√جدید ترین آپدیت فروردین ماه 1404 بسم الله الرحمن الرحیم **کسب درآمد از اینترنت روزانه تا ۲/۰۰۰/۰۰۰ میلیون تومان تضمینی و تست شده** ☆☆آموزش صفر تا صد کسب درآمد اینترنتی بالای ۵۰/۰۰۰/۰۰۰ میلیون تومان ماهانه، پشتیبانی ۲۴ ساعته ۷ روز هفته، ۱۰۰%حلال شرعی، کاملاً واقعی و ... ...
اگر به یک وب سایت یا فروشگاه رایگان با فضای نامحدود و امکانات فراوان نیاز دارید بی درنگ دکمه زیر را کلیک نمایید.
ایجاد وب سایت یا
 کتاب صوتی روانشناسی رشد لورا برک
کتاب صوتی روانشناسی رشد لورا برک فایل صوتی ازدواج بدون شکست
فایل صوتی ازدواج بدون شکست کتاب صوتی انسان روح است نه جسد جلد اول و دوم + pdf (فقط جلد اول پی دی اف موجود می باشد)
کتاب صوتی انسان روح است نه جسد جلد اول و دوم + pdf (فقط جلد اول پی دی اف موجود می باشد) کتاب صوتی شوهر آهو خانم
کتاب صوتی شوهر آهو خانم کتاب صوتی سکس تا فرا آگاهی
کتاب صوتی سکس تا فرا آگاهی کتاب صوتی رمان شب سراب
کتاب صوتی رمان شب سراب کتاب انگیزش و هیجان جان مارشال ریو
کتاب انگیزش و هیجان جان مارشال ریو کتاب صوتی کلیدر از جلد 1 تا 10
کتاب صوتی کلیدر از جلد 1 تا 10 کتاب صوتی راز ثروت شدن من
کتاب صوتی راز ثروت شدن من دانلود رام رسمی هوایی اندروید 5 g610-u20
دانلود رام رسمی هوایی اندروید 5 g610-u20 ماهواره جیبی
ماهواره جیبی تابلو شنی (Sand Picture)
تابلو شنی (Sand Picture) ایده های میلیونی برای شروع یک کسب و کار میلیونی با کمترین سرمایه اولیه
ایده های میلیونی برای شروع یک کسب و کار میلیونی با کمترین سرمایه اولیه فروش صنایع دستی مس
فروش صنایع دستی مس کارگاه خلاقیت مادر و کودک مهر باران
کارگاه خلاقیت مادر و کودک مهر باران سفارشی های امروز جهت فروش
سفارشی های امروز جهت فروش کارگاه کودکان بوژان
کارگاه کودکان بوژان آموزش گام به گام تمام اصول و قواعد کسب درآمد میلیونی از پیام رسان تلگرام
آموزش گام به گام تمام اصول و قواعد کسب درآمد میلیونی از پیام رسان تلگرام کفش ساق دار دخترانه پوما مدل Rihanna
کفش ساق دار دخترانه پوما مدل Rihanna کرم لازان روز یا شب ضد چروک و جلوگیری از چروک مجدد صورت
کرم لازان روز یا شب ضد چروک و جلوگیری از چروک مجدد صورت آموزش مدیتیشن
آموزش مدیتیشن تبلت لنوو مدل Tab 3 7 Essential 3G
تبلت لنوو مدل Tab 3 7 Essential 3G ادکلن زنانه Elegance (الگانس)
ادکلن زنانه Elegance (الگانس) دستگاه تصفیه آب 6 مرحله ای ACE02 ایزی ول
دستگاه تصفیه آب 6 مرحله ای ACE02 ایزی ول ساعت مچی ولار کورنوگراف بند چرم
ساعت مچی ولار کورنوگراف بند چرم سفارش تبلیغات برای کسب کار من
سفارش تبلیغات برای کسب کار من ادکلن مردانه کاپیتان بلک
ادکلن مردانه کاپیتان بلک ساعت پایه دار برنزی
ساعت پایه دار برنزی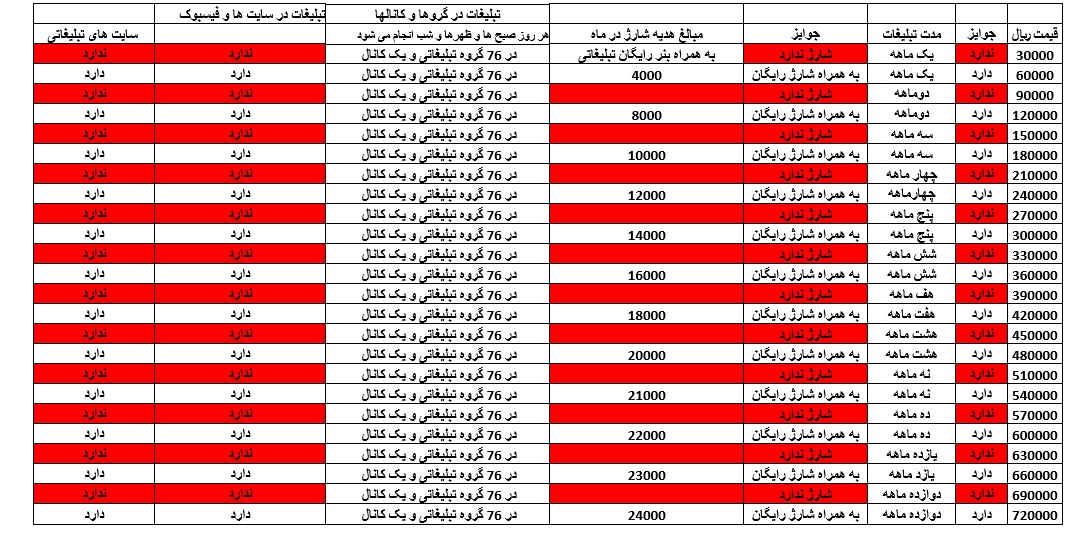 مبلغ پرداخت تبلیغات در سایت پارسا انلاین شاپ کتاب صوتی روانشناسی رشد لورا برک کتاب صوتی انسان روح است نه جسد جلد اول و دوم + pdf (فقط جلد اول پی دی اف موجود می باشد) فایل صوتی ازدواج بدون شکست کتاب صوتی سکس تا فرا آگاهی کتاب انگیزش و هیجان جان مارشال ریو
مبلغ پرداخت تبلیغات در سایت پارسا انلاین شاپ کتاب صوتی روانشناسی رشد لورا برک کتاب صوتی انسان روح است نه جسد جلد اول و دوم + pdf (فقط جلد اول پی دی اف موجود می باشد) فایل صوتی ازدواج بدون شکست کتاب صوتی سکس تا فرا آگاهی کتاب انگیزش و هیجان جان مارشال ریو کتاب صوتی قلعه مالویل کتاب صوتی کلیدر از جلد 1 تا 10
کتاب صوتی قلعه مالویل کتاب صوتی کلیدر از جلد 1 تا 10 کتاب صوتی باغ مارشال جلد 1 تا 3
کتاب صوتی باغ مارشال جلد 1 تا 3 پی دی اف سرانجام جلد 1 و 3
پی دی اف سرانجام جلد 1 و 3 کتاب صوتی موزه معصومیت کتاب صوتی رمان شب سراب
کتاب صوتی موزه معصومیت کتاب صوتی رمان شب سراب کتاب صوتی ذهن هولوتراپیک
کتاب صوتی ذهن هولوتراپیک کسب و کار اینترنتی در منزل
کسب و کار اینترنتی در منزل دانلود نمونه فاکتور آماده با فرمت ورد - اکسل و عکس
دانلود نمونه فاکتور آماده با فرمت ورد - اکسل و عکس درامدزایی در خواب! (تعجب نکنید! بخوانید)
درامدزایی در خواب! (تعجب نکنید! بخوانید) روش اصلی موفقیت در کنکور و آزمون ها(پزشکی، حقوق، مهندسی، نمونه و تیزهوشان) با پکیج کنکورپلاس
روش اصلی موفقیت در کنکور و آزمون ها(پزشکی، حقوق، مهندسی، نمونه و تیزهوشان) با پکیج کنکورپلاس برنامه ساز اندروید و کسب درآمد بالا
برنامه ساز اندروید و کسب درآمد بالا کسب درآمد میلیونی از وبلاگ
کسب درآمد میلیونی از وبلاگ دانلودپکیج ربات فالوور و لایک نامحدود و رایگان اینستاگرام(فوق حرفه ای)
دانلودپکیج ربات فالوور و لایک نامحدود و رایگان اینستاگرام(فوق حرفه ای) چگونه هر کسی را عاشق خود کنیم ؟
چگونه هر کسی را عاشق خود کنیم ؟ کسب درآمد اینترنتی و دائمی به صورت صفر تا صد کار
کسب درآمد اینترنتی و دائمی به صورت صفر تا صد کار کسب در آمد از اینترنت
کسب در آمد از اینترنت کتاب لطفا گوسفند نباشید جلد یک و دو (فارسی)
کتاب لطفا گوسفند نباشید جلد یک و دو (فارسی) کسب درآمد رایگان از سیستم همکاری در فروش
کسب درآمد رایگان از سیستم همکاری در فروش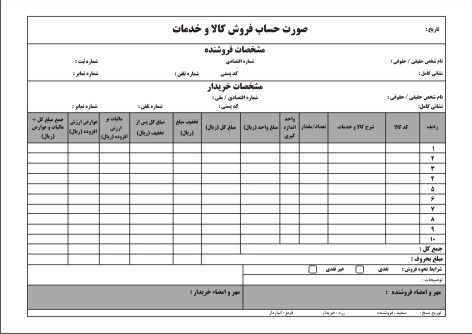 فاکتور فروش رسمی مورد تایید دارایی
فاکتور فروش رسمی مورد تایید دارایی کسب درامد انلاین روزی 500 هزار تومان باروزی 2 ساعت کارتضمینی +هدیه وِیژه
کسب درامد انلاین روزی 500 هزار تومان باروزی 2 ساعت کارتضمینی +هدیه وِیژه پکیج حرفه ای کسب درآمد با گوشی
پکیج حرفه ای کسب درآمد با گوشی آموزش درآمدزایی دائم و پایدار از طریق سایت بیه المللی آمازون
آموزش درآمدزایی دائم و پایدار از طریق سایت بیه المللی آمازون چاپ چک کلیه بانک ها با اکسل
چاپ چک کلیه بانک ها با اکسل بانک شماره تلگرامی های فعال
بانک شماره تلگرامی های فعال کسب درآمد اینترنتی
کسب درآمد اینترنتی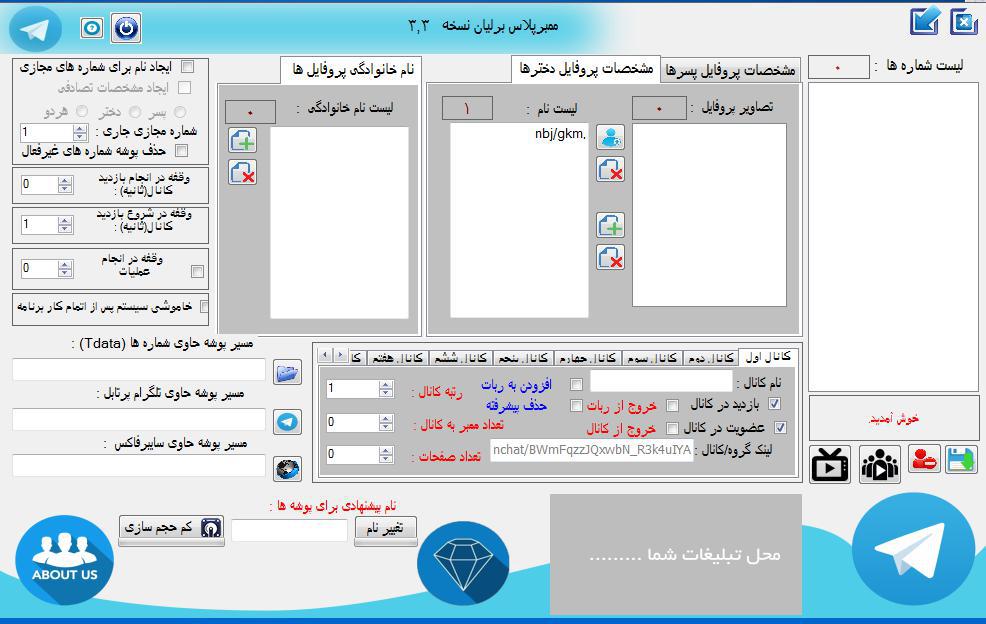 ممبر پلاس برلیان
ممبر پلاس برلیان آموزش گرفتن وام های ميليوني و میلیاردی + طرحهای خدماتی
آموزش گرفتن وام های ميليوني و میلیاردی + طرحهای خدماتی جدول ثبت ورود و خروج کارگران و کارمندان
جدول ثبت ورود و خروج کارگران و کارمندان درآمد ماهانه ۵ ميليون تومان
درآمد ماهانه ۵ ميليون تومان کتاب اسرار خوراکیها بصورت فایل PDF
کتاب اسرار خوراکیها بصورت فایل PDF کسب درامد میلیونی از طریق تلگرام تضمینی وکاملا تست شده
کسب درامد میلیونی از طریق تلگرام تضمینی وکاملا تست شده دانلود نرم افزار اندرویدی سوالات ضمن خدمت فرهنگیان محترم
دانلود نرم افزار اندرویدی سوالات ضمن خدمت فرهنگیان محترم آوریل ۲۰۱۷ / مجله /Architectural Record
آوریل ۲۰۱۷ / مجله /Architectural Record روش تضمینی حل مشکل سیاه یا آبی ماندن/شدن صفحه کامپیوتر یا لپ تاپ
روش تضمینی حل مشکل سیاه یا آبی ماندن/شدن صفحه کامپیوتر یا لپ تاپ ترجمه کتاب چگونه در ۲۸ ماه ۴۶ هزار دلار را به ۵.۶ میلیون دلار تبدیل کنیم؟
ترجمه کتاب چگونه در ۲۸ ماه ۴۶ هزار دلار را به ۵.۶ میلیون دلار تبدیل کنیم؟ پکیج آموزش کسب درآمد میلیونی نوشته هادی طلوعی
پکیج آموزش کسب درآمد میلیونی نوشته هادی طلوعیارسال ایمیل در صورت خرید قبلی supportpurchase@parsaonline-shop.ir





